Why I joined Modular AI?
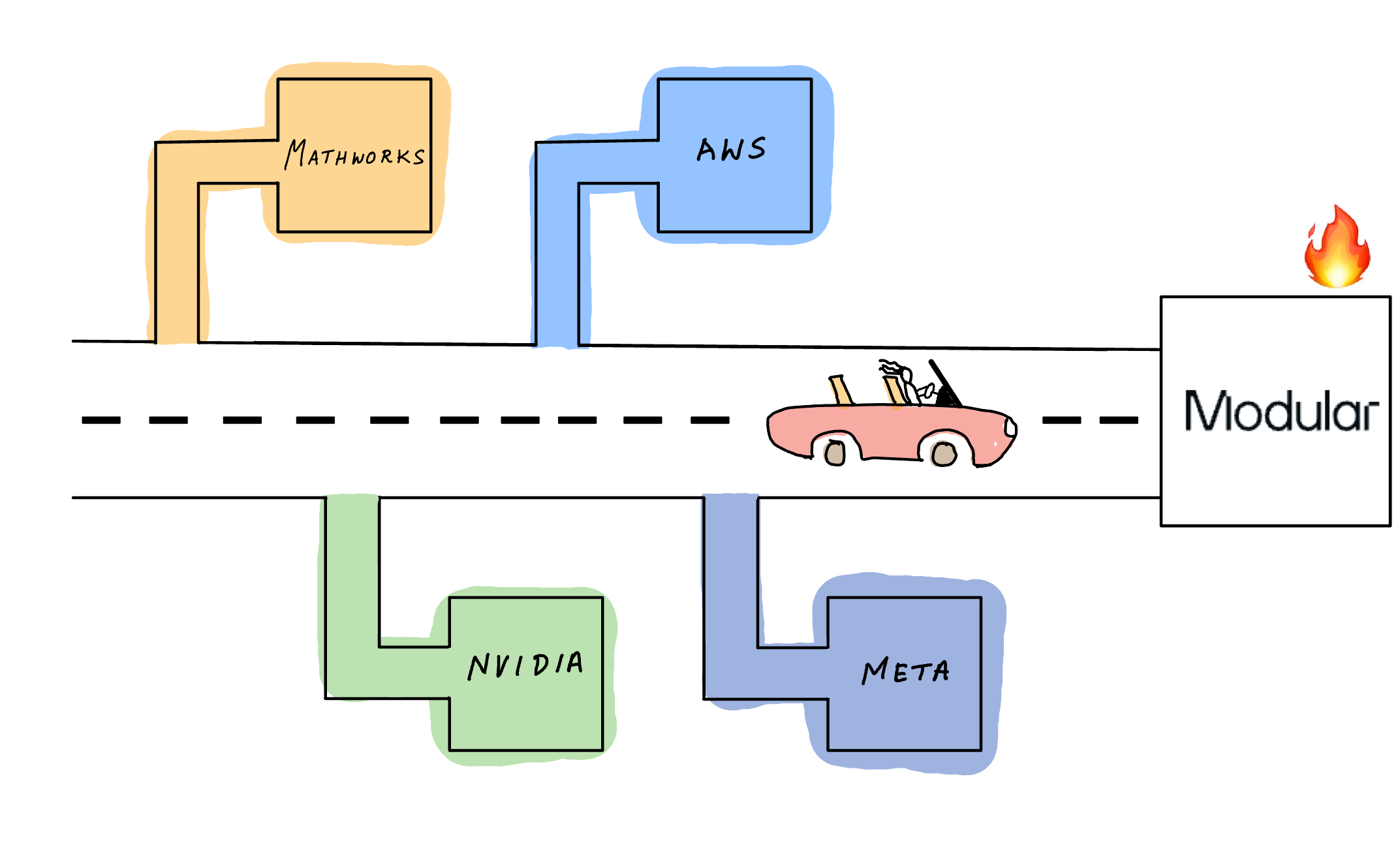 In the past decade, I’ve had the very good fortune of working for companies that make some of the best and proven developer productivity tools. If you’re an engineer who’s built control systems for rockets, cars or robots you’ve used MATLAB and Simulink. If you’re an AI developer you likely have an NVIDIA GPU at arm’s reach (ssh to AWS EC2 counts as arm’s reach). If you’re a developer running software in production you’ve likely relied on AWS services for their scalability and and reliability for deployment. If you’re an AI researcher there is no better tool than PyTorch to go from research paper to trained model.
In the past decade, I’ve had the very good fortune of working for companies that make some of the best and proven developer productivity tools. If you’re an engineer who’s built control systems for rockets, cars or robots you’ve used MATLAB and Simulink. If you’re an AI developer you likely have an NVIDIA GPU at arm’s reach (ssh to AWS EC2 counts as arm’s reach). If you’re a developer running software in production you’ve likely relied on AWS services for their scalability and and reliability for deployment. If you’re an AI researcher there is no better tool than PyTorch to go from research paper to trained model.
What these tools have in common is that they are individually, in my personal opinion, UNPARALLELED at what they do. However, when you start stringing multiple of these tools together, then their productivity promise breaks down. You already know this if you’re training custom models using some or all of these tools. I’ve spend the last several years talking about the the role of AI software and specialized AI hardware and the challenges with using multiple frameworks and AI accelerators during development and deployment and you can read about them in my blog posts.
If you start AI development today, you’ll need answers to these questions before you start your project since it has huge implication on what tools you will use:
During prototyping and development
1. Should you decide on the framework ahead of time (PyTorch, TensorFlow,?) 2. Should you decide where you're going to run it later (GPU, TPU, Intel Habana, AWS Silicon etc.)? 3. Should you write 5 versions of custom layer Op for each potential AI accelerators you want to target? 4. Will your code run as-is when you go from laptop to cloud? on x86 and ARM CPUs? what about GPUs? What about other AI accelerators (AWS Silicon, Intel Habana Gaudi)? 5. Will your code scale out of the box? will it scale on non-GPU AI accelerators? Will it work on all network hardware? between accelerators? between nodes? 6. If you want to write non-ML code (e.g. data processing, control algorithm etc.) will that accelerate on CPUs, GPUs, AI Accelerators? What language do you write it in?
During production deployment
1. What serving framework will you use, was it designed for production or for AI research and prototyping 2. Will it support multiple framework model formats? 3. Does it run on x86, ARM, AI accelerators for inference? 4. Can it run on embedded devices, what architectures are supported? 5. Can it do model parallel on different AI accelerators? 6. Can you meet your target throughput for desired latency at lower cost? 7. Can you monitor performance and accuracy metrics?
It’s exhausting isn’t it?
The disadvantage of using disparate systems is that you risk months or years of reworking, re-tooling and re-implementing when something very small changes, such as - deciding to run on different hardware: GPUs and another AI accelerators, or implement custom models for multiple different frameworks or languages.
Unfortunately, there aren’t a great solutions for these challenges today. What we need a very small, tight set of tools, that is performant, reliable that works well together, runs everywhere and is modular. You see where I’m going with this.
Enter Modular AI
And that brings me to why I decided to join Modular. I share Modular co-founders Chris Lattner (LLVM, Swift) and Tim Davis’s vision that AI tools are broken today and can be better and when fixed, can infinitely improve developer productivity. AI tools can be more usable. AI tools can be more accessible. AI tools can make developers more productive which will make AI itself more accessible to everyone in the world. There will be a future when you don’t have to have answers to the questions ahead of time. You start your work, introduce different hardware, introduce custom models and extensions and stuff will just work. On any system. Deployed anywhere. And you only use one language. And deploy with one runtime engine.
If I’ve piqued your interest, come check out the products we’re building at Modular AI:
- Mojo🔥 programming language that combines the usability of Python with the performance of C. You can write your custom kernels and ops in Mojo, so your entire stack that’ll run on multiple AI accelerators is in one language which is a superset of Python!
- Modular Engine is an AI inference engine built with Mojo🔥 that gives you unparalleled performance and runs PyTorch and TensorFlow models on multiple hardware.
Good tools make us productive, they bring us joy, the same joy you get when you find the right screw driver for that pesky loose screw, the right sized wrench, the right drill - no other makeshift tool will bring you that satisfaction of the right tool for the job. Practitioners in every domain need tools to build, create, solve, and implement more efficiently and AI is no different. We need better AI tools for developers and I believe Modular will play a significant role in building them.
We’re in early days, and Mojo and Modular Engine are not generally available yet, but you can try Mojo in the Mojo playground and see the performance speedups for yourself. Signup here to get access to Mojo playground and learn more about other Modular products. Follow me on Twitter @shshnkp, read my blog posts on Medium (and here) @shashank.prasanna and connect with me on LinkedIn as I’ll be sharing a Modular’s journey and educational content. Thanks for reading!