How Docker Runs Machine Learning on NVIDIA GPUs, AWS Inferentia, and Other Hardware AI Accelerators
illustration by author
If you told me a few years ago that data scientists would be using Docker containers in their day to day work, I wouldn’t have believed you. As a member of the broader machine learning (ML) community I always considered Docker, Kubernetes, Swarm (remember that?) exotic infrastructure tools for IT/Ops experts. Today it’s a different story, rarely a day goes by when I don’t use a Docker container for training or hosting a model.
An attribute of machine learning development that makes it different from traditional software development is that it relies on specialized hardware such as GPUs, Habana Gaudi, AWS Inferentia to accelerate training and inference. This makes it challenging to have containerized deployments that are hardware-agnostic, which is one of the key benefits of containers. In this blog post I’ll discuss how Docker and container technologies have evolved to address this challenge. We’ll discuss:
- Why Docker has become an essential tool for machine learning today and how it addresses machine learning specific challenges
- How Docker accesses specialized hardware resources on heterogeneous systems that have more than one type of processor (CPU + AI accelerators).
- How different AI accelerators extend Docker for hardware access with examples of 1/ NVIDIA GPUs and NVIDIA Container Toolkit and 2/ AWS Inferentia and Neuron SDK support for containers
- How to scale Docker containers on Kubernetes with hardware accelerated nodes
A large part of this blog post is motiviation and “how it works under the hood”, but I also include walkthroughs, links and screenshots on how you can get started with Docker containers on NVIDIA GPUs or AWS Inferentia on AWS, so there is something in here for both the learner and the practitioner.
Docker and machine learning didn’t grow up together (but they’re best friends now)
Most organizations today use Docker and container technologies to simplify the development and deployment process since containerized applications are consistent, portable and guarantee reproducibility. While Docker containers are supposed to be both hardware-agnostic and platform-agnostic, most machine learning based software stack is hardware-specific and needs access to the hardware and hardware drivers on the host OS. To understand the issue better, let’s take a closer look at the anatomy of a typical machine learning software stack.
Anatomy of a typical machine learning software stack
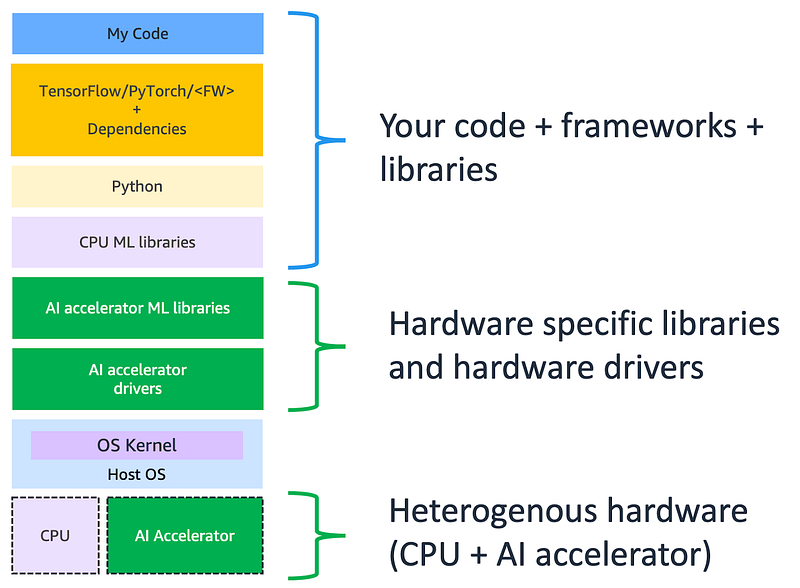
illustration by author
The software stack shown in the illustration above looks quite typical to start with. The top section shown with blue curly brace includes your code, frameworks that you’re working with, languages and other lower level libraries. This section looks similar regardless of what applications, frameworks or languages you’re using. The rest of the stack is where things start to look unique for machine learning. The green boxes are hardware specific components that affects portability, here’s what they do:
- AI accelerator ML libraries: These are low level libraries that are used by ML frameworks to implement machine learning training or inference routines on AI accelerator hardware. They implement linear algebra and other computationally intensive routines that can be parallelized and run on AI accelerators.
- AI accelerator drivers: These are drivers that the host OS uses to recognize and support the AI accelerator hardware.
- AI Accelerator: This is a dedicated processor designed to accelerate machine learning computations. Machine learning is primarily composed of matrix-matrix math operations and these specialized hardware processors are designed to accelerate these computations by exploiting parallelism. You can read more about AI accelerators in other blog posts: 1/ Guide to AI accelerators 2/ Evolution of AI accelerators
Systems that have a CPU + other types of processors are called heterogeneous systems. Heterogeneous systems improve performance and efficiency, as there are dedicated processors for specific tasks, but come at the cost of increased complexity. This increased complexity introduces challenges with portability of the software stack and developer user experience. This is the challenge Docker has to address, and we’ll see below how it does that.
How does Docker support host devices?
By default Docker containers don’t have access to host OS resources and this is by design. Docker containers are intended to offer process isolation, therefore the user has to provide explicit access to host resources such as volumes and devices. You can do that by using the —-devices argument but it comes with a few caveats.
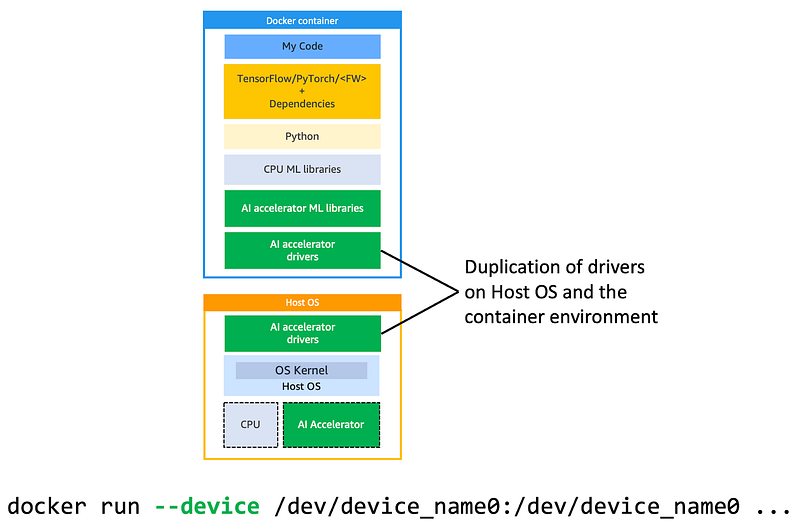
illustration by author
Some hardware devices such as USB and serial devices have drivers that run in the kernel space and Docker must rely on the host kernel and perform system calls to interact with the device hardware. These devices are easily accessed inside the Docker container process using the--device argument and mounting the device. However, other hardware devices such as some network cards and AI accelerators have drivers that have a user space component and a kernel space module. In this case, you will need to duplicate the install of the driver in the host OS and the Docker container.
Let’s say you want to launch a container process and you want to expose a device called device_name0 then you’d run the following command:
docker run --device /dev/device_name0:/dev/device_name0 …
If device_name0 has both a user space and kernel space driver components then you must also install the device driver inside the Docker container, which duplicates the driver on the host and container environment as shown in the illustration at the top of this section.
This setup comes with a few disadvantages:
- Increased container size: Containers are supposed to be lightweight and portable and drivers are often large and take up a lot of space. For example the latest NVIDIA GPU drivers can take between 350 to 500 MB of additional space in your container. This adds to container image download and instantiation time and which can affect latency sensitivity applications and user experience
- Driver version mis-match: For this solution to work, the driver versions in the container environment and host OS must match. If they are different, the container process may not be able to talk to the hardware.
- Setup complexity : Installing Drivers in containers are extra steps and every extra library or software you put in a container adds additional complexity and needs to be tested.
- Decreased portability: Docker containers were designed to be light-weight, portable and hardware-agnostic. Drivers in the containers make it heavy, hardware-specific, platform-specific, and basically un-does all the benefits of Docker containers.
At the minimum, the goal should be to address these challenges with a solution that doesn’t require device drivers to be duplicated inside the container and allow Docker to pin access to some or all the AI accelerators on the system with multiple accelerators. Let’s now take a look at how Docker address this challenge.
How do we make Docker work with specialized machine learning hardware?

illustration by author
We’ll start with a quick high-level recap on how Docker runs containers. When you use the Docker CLI to start a container process using docker run … a sequence of steps take place before it eventually calls a very important library called runC.
runC is an Open Container Initiative (OCI) compliant tool for spawning and running container processes that is used by Docker, Podman, CRI-O and other popular container runtimes. When you use the Docker CLI to run a container, Docker provides runC with an OCI compliant runtime specification file (shown in the image as “OCI spec”) and container’s root filesystem together called a OCI compliant Bundle, which runC takes as inputs to create and run the container process. The OCI spec file has provisions for including additional options such as pre-start and post-start hooks to launch other processes before and after container processing creation. Hardware providers can take advantage of these hook to inject hardware access to the container process. Let’s see how.
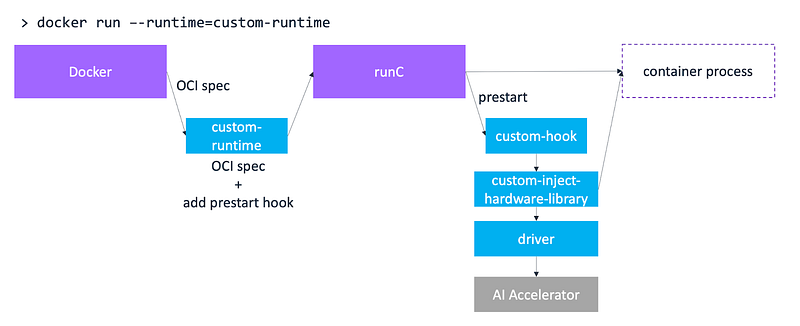
Generic template for introducing AI accelerator support to Docker. illustration by author
AI accelerator providers can extend the functionality of runC using the pre-start hooks to hook into a container’s lifecycle with an external application. This external application is typically a library that talks to the hardware driver and exposes the hardware inside the container process. The blue boxes in the illustration above show how you can use Docker and runC features to advertise specialized hardware to a container process. Let’s take a looks the components in this this generic template for implementing specialized hardware support in Docker containers:
- custom-runtime: Docker allows you to define a custom runtime using
/etc/docker/daemon.json. Using the custom runtime, you can intercept the OCI specification you receive from Docker, add a pre-start hook and forward the updated specification torunC. - custom-hook:
runCreads the pre-start hook from the specification it received from the custom runtime, and executes the custom-hook. This custom-hook calls a hardware-specific library or libraries that can talk to the hardware driver and expose it in the container process - custom-inject-hardware-library: This library is responsible for communicating with the hardware driver to gather information about the hardware and number of processors in the system. It’s also responsible for mounting the hardware device into the container environment and making it available for applications in the container process.
Below, we’ll take a look at how Docker can access NVIDIA GPUs and AWS Inferentia.
Launching NVIDIA GPU and AWS Inferentia Amazon EC2 instances
First we’ll launch Amazon EC2 instances to demonstrate how Docker works with specialized hardware. Follow this guide to launch an EC2 instance for machine learning. For NVIDIA GPUs choose any size of P or G family of instance types. If you need help choosing the right GPU for deep learning on AWS read my blog post:
For AWS Inferentia instances choose an Inf1 instance type. In this example, I launch inf1.2xlarge (AWS Inferentia) and p3.8xlarge (4 x NVIDIA V100 GPUs).
Once you’ve chosen your instance type, you have to choose an Amazon Machine Image (AMI), and we’ll use the AWS Deep Learning AMI which comes with GPU drivers, AWS Inferentia drivers, deep learning frameworks, conda and other tools pre-installed. Choose an AMI with the right type and version of the deep learning framework you need for your work, for this example I’ll be choosing the Multi-framework DLAMI for Ubuntu 18.04.
After you’ve launched your Amazon EC2 instances you can see them on your EC2 console and you can ssh into them to run your applications. You can also read my blog post on Why use Docker containers for machine learning development? for a walkthrough of how to ssh and set up a jupyter server in a Docker container running on EC2.
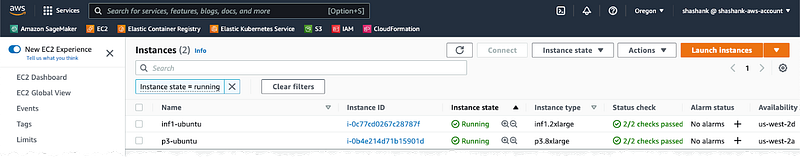
Screenshot of Amazon EC2 console
Accessing NVIDIA GPUs in Docker containers
NVIDIA offers the NVIDIA Container Toolkit, a collection of tools and libraries that adds support for GPUs in Docker containers.
docker run --runtime=nvidia --gpus=all …
When you run the above command, NVIDIA Container Toolkit ensures that GPUs on the system are accessible in the container process. Since we launched an Amazon EC2 instance with AWS Deep Learning AMI, you won’t need to install the NVIDIA Container Toolkit as it comes pre-installed. If you’re starting with a base AMI follow the install instruction on NVIDIA Container Toolkit documentation.
How NVIDIA Container Toolkit works
NVIDIA Container Toolkit includes nvidia-container-runtime, nvidia-container-runtime-hook and libnvidia-container. Let’s take a look at how these work.
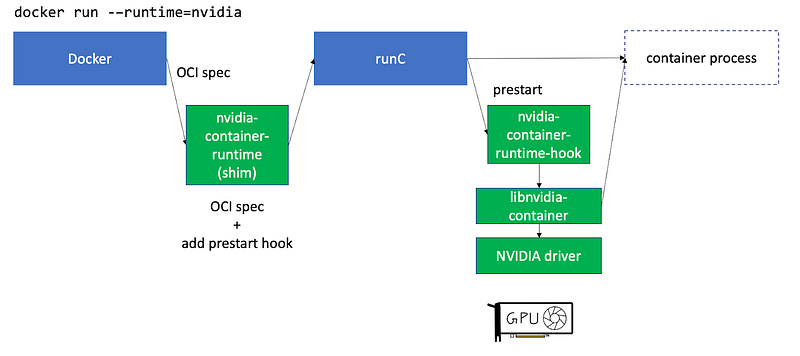
illustration by author
NVIDIA Container Toolkit registers a custom runtime by specifying it in /etc/docker/daemon.json. This custom runtime is a shim that takes the runtime specification from Docker, modifies it to the pre-start hook specification and forwards the spec to runC.

screenshot showing custom nvidia runtime that Docker invokes
NVIDIA Container Toolkit also allows you to configure the container runtime using file based config. You can edit /etc/nvidia-container-runtime/config.toml file to specify different locations for your drivers, runtime, change default runtime, enable debugging etc. You can leave the defaults if you don’t have a custom setup.
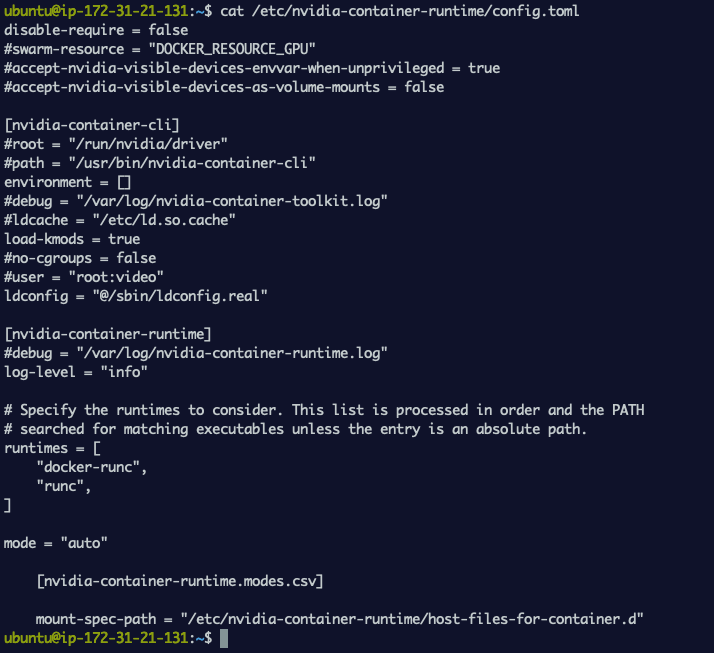
screenshot showing config.toml
Let’s say you ran the following command
docker run --runtime=nvidia --gpus=2 …
Docker takes the command line arguments and translates it into a OCI compliant runtime spec. nvidia-container-runtime adds the pre-start to this specification and passes it on to runC. Next, runC sees the pre-start hook in the modified spec and calls the nvidia-container-runtime-hook before starting the container process. The nvidia-container-runtime-hook looks at the container runtime config to determine what GPUs or how many GPUs you requested to expose in the container process. Next, it calls libnvidia-container library which talks to the NVIDIA driver to determine if the requested number of GPUs (In this example we said--gpus=2) are available and if they are, it injects those GPU devices into the container.
To test GPU access, I’m going to pull down a Pytorch container from the list of deep learning containers Amazon hosts on Amazon ECR. Follow the instructions in that page to log into Amazon ECR and run docker pull <IMAGE_NAME>. Then run the following command to launch the container.
docker run -it --rm --runtime=nvidia — gpus=all <IMAGE_NAME/ID> nvidia-smi
We can see from the output that I can run nvidia-smi a tool that queries and displays all 4 GPUs available on this EC2 instance and can be accessed from within the container.
Note:--runtime=nvidia is optional if you’re using a recent versions of Docker and NVIDIA Container Toolkit
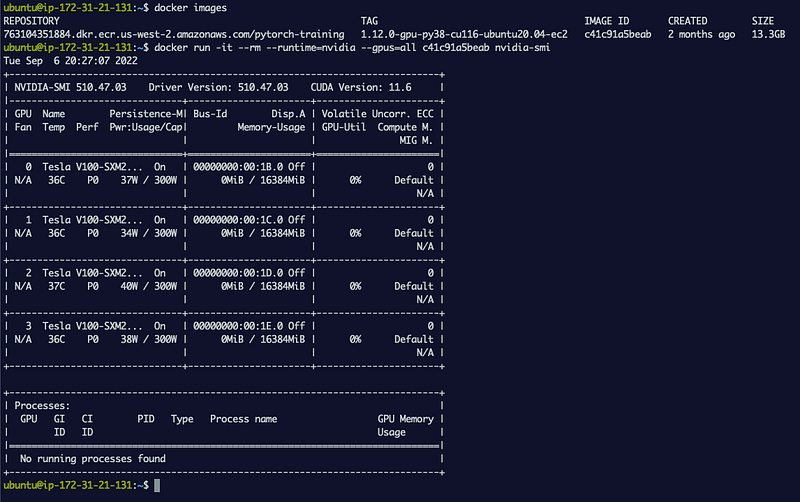
screenshot showing output of nvidia-smi running inside a Docker container showing all GPUs
If you want to expose only 2 GPUs inside the container then you can simply specify –-gpus=2 or enumerate which two you want available inside the container:
docker run -it — rm — runtime=nvidia — gpus=2 <IMAGE_NAME/ID> nvidia-smi
# OR
docker run -it — rm — runtime=nvidia — gpus=’”device=0,1"’ <IMAGE_NAME/ID> nvidia-smi
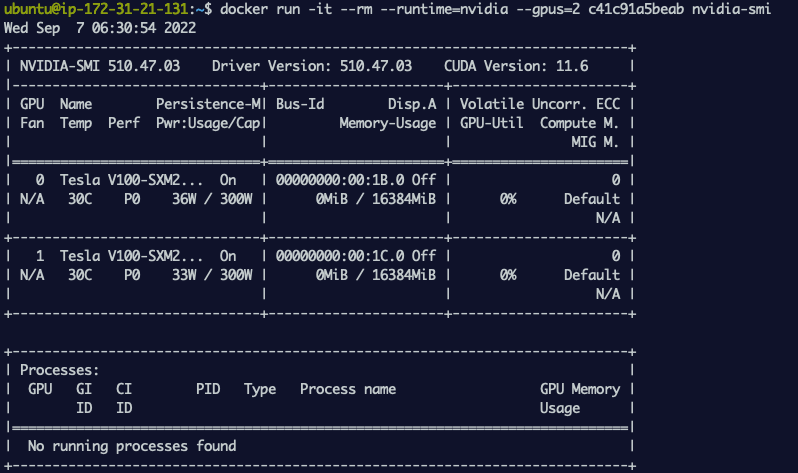
screenshot showing output of nvidia-smi running inside a Docker container showing only 2 GPUs
Accessing AWS Inferentia accelerators in Docker containers
To prepare your Inf1 Amazon EC2 instance with AWS Inferentia, you can follow the steps in the AWS Neuron documentation to install the Neuron drivers, Neuron runtime and a helper library called oci-add-hooks which facilitates adding OCI neuron pre-start hooks.
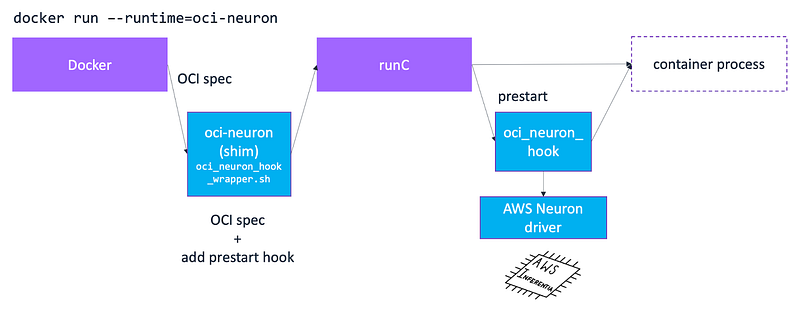
illustration by author
How Docker support AWS Inferentia works
After you’ve installed the Neuron SDK and followed the Docker environment setup steps, your system should have oci-neuron-runtime, oci-neuron-hook. Let’s take a look at how they work.
screenshot showing neuron runtime
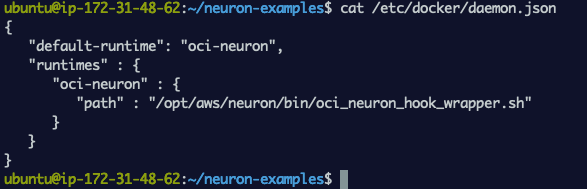
Similar to NVIDIA Container Toolkit, Neuron SDK registers a custom runtime by specifying it in /etc/docker/daemon.json. From the screenshot below, you can see that the custom Docker runtime is just a shell script. Recall the role of the custom runtime is to simply intercept the call to runC, modify it to include a pre-start hook specification and call runC with the updated spec.

screenshot showing neuron hook shim
Let’s open open oci_neuron_hook_wrapper.sh see what it’s doing:
- Specifies the path to the location of
oci_neuron_hook_config.json, a JSON file that defines what library the pre-start hook should call - Gets the location of
runClibrary - Uses
oci-add-hooks, a tool that can take a pre-start hook definition from a file calledoci_neuron_hook_config.jsonand generate an updated runtime spec and pass it along torunC
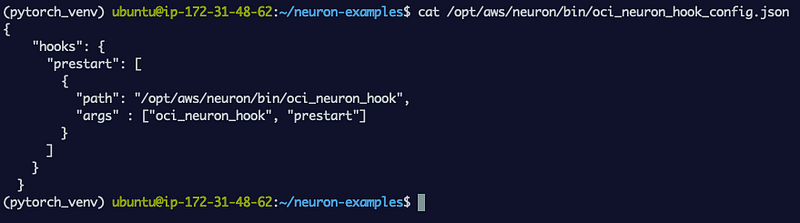
We can open oci_neuron_hook_config.json and you can see oci_neuron_hook which is the library that’s invoked by runC prior to creating the container process.
screenshot showing hook configuration
oci_neuron_hook library talks to the AWS Inferentia driver to determine if the requested number of AWS Inferentia devices are available and if they are, it injects those devices into the container. To test AWS Inferentia support in Docker, download the following Docker file and run:
docker build . -f Dockerfile.app -t neuron-test
docker images
And you should see a neuron-test image
screenshot showing the docker image to test neuron
Launch the container
docker run — env — runtime=oci-neuron AWS_NEURON_VISIBLE_DEVICES=”0" neuron-test neuron-ls

screenshot showing output of neuron-ls running inside a Docker container
And you can see that Neuron Device 0 is shown by the output of neuron-ls which was executed inside the container process. Note: –-runtime=oci-neuron is optional as neuron is the default runtime as you can see below.
screenshot showing that neuron runtime as the default runtime
Kubernetes support for NVIDIA GPUs and AWS Inferentia
So far we’ve seen how Docker can provide access to specialized hardware such as NVIDIA GPUs and AWS Inferentia inside a container, this allows for more portable machine learning code. The natural next step is to figure out how to run these Docker containers on an orchestration system like Kubernetes so you can run large-scale deployments. This topic deserves it own detailed blog post, but I’ll aim to quickly summarize how you can access AI accelerator resources in Kubernetes for sake of completeness.
For both NVIDIA and AWS Inferentia, each Kubernetes node’s host OS must include the relevant hardware drivers, custom container runtimes and other libraries we discussed earlier that enable specialized hardware support within Docker containers. The easiest way to launch an Amazon EKS cluster is to use the eksctl CLI tool.
- For NVIDIA GPUs nodes specify an Amazon Deep Learning AMI as the AMI for your nodes in
eksctlas that it comes with NVIDIA Container Toolkit pre-installed. - For AWS Inferentia nodes the
eksctltool will automatically detects that you have a node with AWS Inferentia and will use an Amazon Linux AMIs with Neuron SDK, drivers and Docker support libraries preinstalled.
Next, to make these AI accelerators available as a system resource within Kubernetes, you’ll need to deploy a Kubernetes device plugin specific to the hardware. Both NVIDIA and AWS provide device plugins that you can apply as follows:
AWS Inferentia:
kubectl apply -f k8s-neuron-device-plugin.yml
This device plugin which you can download from the Neuron SDK documentation, runs as a daemonset and advertises hardware to containres within pods and you can specify AWS Inferentia hardware under resources in the manifest as follows:
resources:
limits:
aws.amazon.com/neuron: 1
NVIDIA GPUs:
kubectl apply -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v1.12/nvidia-device-plugin.yml
This NVIDIA device plugin also runs as a daemonset and advertises hardware to pods and you can specify NVIDIA GPU hardware under resources in the manifest as follows:
resources:
limits:
nvidia.com/gpu: 1
You can find more detailed instructions on how to get started for both AWS Inferentia and NVIDIA GPU on the Amazon EKS documentation pages.
Closing (and yes, there is a video!)
Hope you enjoyed learning about how Docker runs on specialized hardware and how to use it. If you enjoyed this blog post, I recently gave a talk on the same topic that you might find interesting.
YouTube video on how Docker runs machine learning on AI accelerators
Thank you for reading to the end!
If you found this article interesting, consider following me on medium to be notified when I publish new articles. Please also check out my other blog posts on medium or follow me on twitter (@shshnkp), LinkedIn or leave a comment below. Want me to write on a specific machine learning topic? I’d love to hear from you!